003 HTTP
# 001 报文结构
# 起始行
GET /home HTTP/1.1
方法 + 路径 + 协议
# 头部
字段名+字段值
如:date: Wed, 26 Jan 2022 05:46:51 GMT
格式:
- 字段名不区分大小写
- 字段名不能出现空格及下划线
- 必须加
:
# 空行
用于分割头部与实体
# 实体
具体数据,请求报文对应请求体,响应报文对应响应体
# 002 HTTP 请求方式
# 请求方法
- GET:提交、获取资源
- POST:提交、获取资源
- PUT:修改数据
- DELECT:删除数据
- OPTIONS:列出可对资源实行的请求方法,用于跨域
- HEAD:获取资源元信息
- CONNECT:建立连接通道,用于代理服务器
- TRACE:追踪请求-响应的传输路径
# GET 与 POST
开始之前我们先看一下标准答案

从标准上看有以下区别
- GET 用于获取信息,是无副作用的,是幂等的,且可缓存
- POST 用于修改服务器上的数据,有副作用,非幂等,不可缓存
幂等:任意多次执行所产生的影响均与一次执行的影响相同 (如: setTrue() )
在带参数的报文中,GET 的参数在url中,POST 的参数则在 body 中
# 报文区别
如:参数 username:admin
GET 的简约报文为
GET /index.php?username=admin HTTP/1.1
POST 的简约报文为
POST /index.php HTTP/1.1
Host: localhost
username=admin
2
3
4
# 无关安全问题
有些解释认为POST 比 GET 安全,因为POST不会在地址栏显示数据
但从传输角度来说,两者都是不安全的,因为 HTTP 是明文传输协议,想要数据安全只有加密 也就是 HTTPS
# GET 的长度限制
在网上看到很多关于两者区别的文章都有这一条,提到浏览器地址栏输入的参数是有限的
但是 HTTP 并没有 body 和 url 长度的相关限制,对 URL 限制主要是在 浏览器 和 服务器
# POST 方法会产生两个TCP数据包?
有些文章称
post 会将 header 和 body 分开发送,先发送 header,服务端返回 100 状态码再发送 body
但HTTP 协议中没有明确说明 POST 会产生两个 TCP 数据包,而且经过(chrome)实测也并未将header与body分开
所以,分开发送可能是某些浏览器的特殊请求方法,不属于 POST 行为
# 总结
- 从缓存角度:GET有缓存留下历史记录,而 POST 默认不会
- 从报文角度:两个存在报文结构差别
- 从幂等角度:GET 幂等,POST 非幂等
- 从编码角度:GET 只接收 ASCII 字符,POST 无限制
# 003 理解 URI
URI, 全称为(Uniform Resource Identifier), 也就是统一资源标识符,它的作用很简单,就是区分互联网上不同的资源,URI 完整结构:

# 结构
- scheme 表示协议名,比如
http,https,file等等。后面必须和://连在一起 - user:passwd@ 表示登录主机时的用户信息,不过很不安全,不推荐使用,也不常用
- host:port表示主机名和端口
- path:表示请求路径,标记资源所在位置
- query:表示查询参数,为
key=val这种形式,多个键值对之间用&隔开 - fragment:表示 URI 所定位的资源内的一个锚点,浏览器可以根据这个锚点跳转到对应的位置
# URI 编码
URI 只能使用ASCII, ASCII 之外的字符是不支持显示的;
因此,URI 引入了编码机制,将所有非 ASCII 码字符和界定符转为十六进制字节值,然后在前面加个%
# 004 HTTP 状态码
这里有一览表runoob (opens new window)
着重注意下 301 永久重定向和302临时重定向
# 005 HTTP的主要问题
# 明文传输
即协议里的报文(主要指的是头部)不使用二进制数据,而是文本形式,让 HTTP 的报文信息暴露给了外界
# 队头阻塞
由于浏览器的TCP连接数是有限的,那么当前请求耗时过长的情况下,其它的请求只能处于阻塞状态(除了2.0:http 2.0 实现了并发)
# 006 Accept、Content系列字段
# 数据格式
Accept 用于让接收端指定数据格式,而相对的用于标记报文 body 部分的数据格式则用 Content-Type
这两个字段的取值可以分为下面几类:
- text: text/html, text/plain, text/css 等
- image: image/gif, image/jpeg, image/png 等
- audio/video: audio/mpeg, video/mp4 等
- application: application/json, application/javascript, application/pdf, application/octet-stream
# 压缩方式
当然一般这些数据都是会进行编码压缩的,采取什么样的压缩方式就体现在了发送方的Content-Encoding字段上相对的在接受方的Accept-Encoding字段上
// 发送端
Content-Encoding: gzip
// 接收端
Accept-Encoding: gzip
2
3
4
# 支持语言
在需要实现国际化的方案当中,在发送方对应的字段为Content-Language,在接受方对应的字段为Accept-Language
// 发送端
Content-Language: zh-CN, zh, en
// 接收端
Accept-Language: zh-CN, zh, en
2
3
4
# 字符集
指定可以接受的字符集,由于发送端没有对应的字段,所以该值被放在了发送端的Content-Type中
// 发送端
Content-Type: text/html; charset=utf-8
// 接收端
Accept-Charset: charset=utf-8
2
3
4
# 007 数据长度
# 定长体
对于定长体而言,发送端在传输的时候一般会带上 Content-Length, 来指明包体的长度,Content-Length对于 http 传输过程起到了十分关键的作用,如果设置不当可以直接导致传输失败
# 不定长
通过设置字段
Transfer-Encoding: chunked
表示分块传输数据,设置这个字段后会自动产生两个效果:
- Content-Length 字段会被忽略
- 基于长连接持续推送动态内容
# 008 HTTP 大文件传输
# 009 ⭐HTTP 表单提交
在 HTTP 中表单提交主要体现在两种 Content-Type 值:
- application/x-www-form-urlencoded
- multipart/form-data
# application/x-www-form-urlencoded
这种数据格式的表单内容,有以下特点:
- 其中的数据会被编码成以
&分隔的键值对 - 字符以URL编码方式编码
{a: 1, b: 2} -> a=1&b=2 -> "a%3D1%26b%3D2" // 转为 URL 编码
# multipart/form-data
请求头中的 Content-Type字段会包含boundary字段,这个字段的值由浏览器默认指定,用于分割多个数据,它会将表单的数据处理为一条消息,以标签为单元,用分隔符分开。既可以上传键值对,也可以上传文件。当上传的字段是文件时,会有Content-Type来表名文件类型。
# 010 HTTP 队头阻塞
由于 HTTP 传输是基于请求-应答的模式进行的,报文必须是一发一收,那么就导致在早期版本中会出现队首处理太慢阻塞后面请求的处理,后来经过迭代才改善这个问题,主要体现在以下几个版本中:
# HTTP1
每一次 HTTP 请求,就要建立一个 TCP 链接,用完就断开
# HTTP 1.1
固 HTTP 1.1 诞生: HTTP 1.1 加入了 Keep-Alive ,只要 TCP 链接没断就能一直发送HTTP请求,但问题还没解决,这个协议模型本身还是在 HTTP/1.0 上修修补补,缺点还是有的,也就是同一个 TCP 链接上,多个 HTTP 请求彼此间是阻塞的,也就是请求 A 先得到响应后,请求 B 才会开始发送。 那么有读者就要问了为什么控制台上看起来是并发了。其实实现并发只能建立多个TCP链接,各个浏览器各有不同 如 Chrome 为6个、Safari 4 个、IE则各版本不同,也就是说一个域名可以同时建立6个TCP连接,以此来并发6个HTTP请求。(但是后端也同样可以限制并发个数)
# 拓展域名分片
以 chrome 为例,如果 6 个连接依然不能满足产品需求,那应该怎么办呢?那么我们可以多分几个域名,比如我们可以拆分出 content1.api.com 和 content2.api.com,这样我们就可以建立12个连接了,事实上也更好地解决了队头阻塞的问题,但是本质上不可能套娃似的无限叠加,知道 2.0 出现
# HTTP2.0
HTTP 2.0:2.0真正意义上实现了 HTTP 并发,一个 tcp 连接可以并发多个 HTTP 请求,请求官网 https://http2.akamai.com/demo 打开控制台,可以看到并发了上百个请求,目前已经有许多大厂支持了 HTTP2.0了
# 总结
HTTP 并发数取决于 HTTP 协议、浏览器限制、后端限制
# 011 Cookie
# 使用
前面说到了 HTTP 是一个无状态的协议,每次 http 请求都是独立的,默认不需要保留状态信息。
HTTP 为此引入了 Cookie ,Cookie 本质上是一个存储在客户端的一个很小的文件,文件内以键值对的方式存储。当客户端向同一域名发起请求时,就会带上相同的 Cookie ,服务器便可以拿到 Cookie 进行解析。
而服务端则通过 响应头的Set-Cookie字段来对客户端写入 Cookie, 如:
// 响应头
Set-Cookie: ge_wms_session=eyJpdiI6Ildsa01mVG03NFUyQlEyVDNteFY; expires=Thu, 27-Jan-2022 08:52:40 GMT; Max-Age=7200; path=/; httponly
// 请求头
Cookie: ge_wms_session=eyJpdiI6Ildsa01mVG03NFUyQlEyVDNteFY
2
3
4
# 属性
# 有效期
Cookie 的有效期可以通过Expires和Max-Age两个属性来设置
- Expires:指定一个绝对的过期时间(GMT格式)
- max-age:指定的是从文档被访问后的存活时间,这个时间是个相对值(比如:3600s),相对的是文档第一次被请求时服务器记录的Request_time(请求时间)
# 作用域
同样由两个字段进行设置
- path: Cookie的使用路径。如果设置为“/sessionWeb/”,则只有contextPath为“/sessionWeb”的程序可以访问该Cookie。如果设置为“/”,则本域名下contextPath都可以访问该Cookie。注意最后一个字符必须为“/”
- domain:可以访问该Cookie的域名。如果设置为“.google.com”,则所有以“google.com”结尾的域名都可以访问该Cookie。注意第一个字符必须为“.”
# 安全
如果带上Secure,说明只能通过 HTTPS 传输 cookie
如果 cookie 字段带上HttpOnly,那么说明只能通过 HTTP 协议传输,不能通过 JS 访问,这也是预防 XSS 攻击的重要手段
相应的,对于 CSRF 攻击的预防,也有SameSite属性
# 012 ⭐HTTP 缓存
浏览器缓存分为两种:强缓存、协议缓存
# 强缓存
当首次请求一个页面时,浏览器便会根据响应头来判断是否需要对资源进行缓存,如果响应头存在 expires | pragma | cache-control 字段,则代表这是强缓存,浏览器就会把资源存在 memory cache 或者 disk cache 中。
第二次请求:此时浏览器会判断请求参数,如果符合强缓存条件,则直接返回状态码200,并从本地缓存中拿数据。
不符合则将响应参数存在 request header 请求头中,看是否符合协议缓存, 符合则返回状态码 304,不符合则返回全新资源。
# expires
该值为一个事件戳(格林尼治时间),用来表示该资源的到期时间。当再次发起请求时,如果未超过过期时间,直接使用缓存,否则重新请求。
缺点是判断是否过期是根据本地时间进行判断的。
# Cache-Control
当 cache-control 存在时,优先级更高主要用于验证强缓存是否可用,字段值主要有:
- public:资源客户端和服务器都可以缓存
- privite:资源只有客户端可以缓存
- no-cache:客户端缓存资源,但是是否使用缓存还需要经过协商缓存验证
- no-store:不使用缓存
- max-age:缓存有效期
# pragma
HTTP 1.0 中禁用网页缓存的字段,取值为no-cache,一倍 1.1 中的 cache-control 替代
# 缓存位置
强缓存会将资源放到memory cache 和 disk cache 中,通过开发者工具我们可以清晰地看到缓存资源的调用:

查找浏览器缓存时会按顺序查找:
Service Worker --> Memory Cache --> Disk Cache --> Push Cache
# 协商缓存
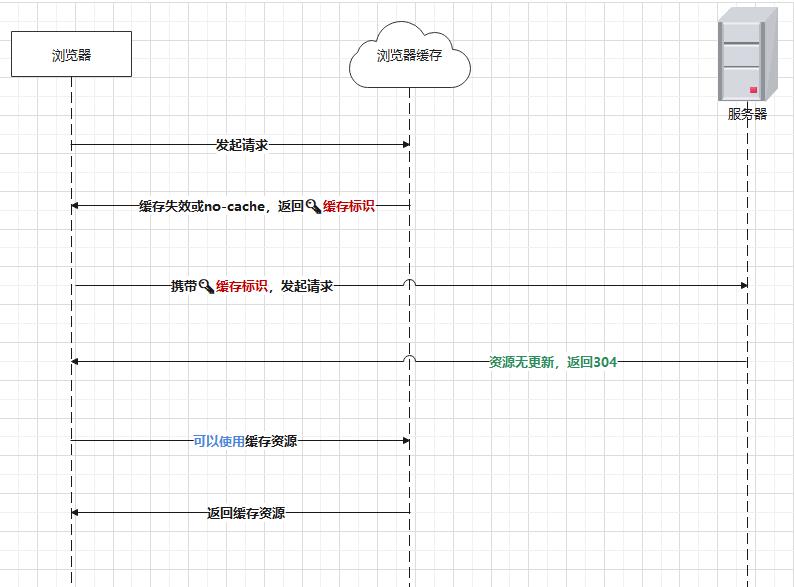
协商缓存是在强缓存失效后,浏览器携带缓存标识向服务器发送请求,然后由服务器根据缓存标识决定是否使用缓存的过程。比如 no-cache 并非不使用缓存,而是使用缓存需要进行一次协商,协商有两种结果:
# 协商生效
协商生效时,返回 304 并使用缓存结果
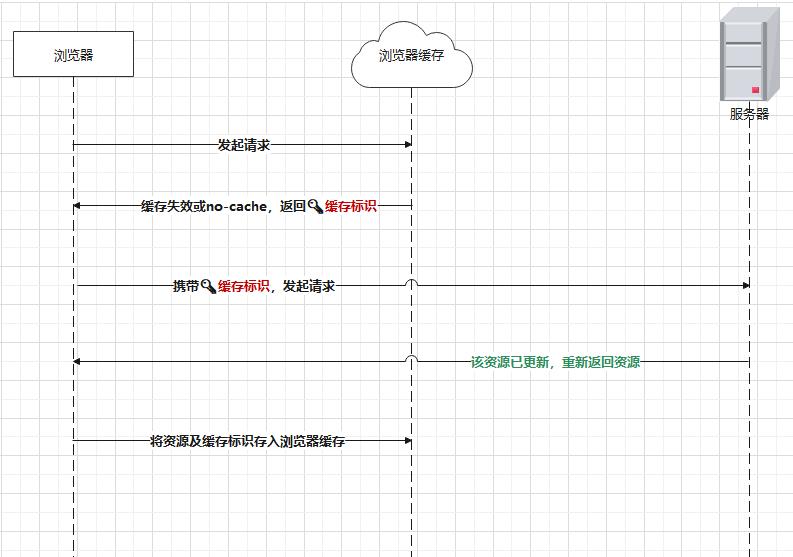
# 协商失效
协商结果为失效时,重新返回 200 及请求结果
# 如何设置协商缓存
lost-modified / if-modified-since:
服务端通过响应头字段 last-modified 返回一个该资源在服务器中最后的修改时间,如:
lost-modified: Mon, 29 Nov 2021 08:08:24 GMT
客服端通过请求头字段 if-modified-since 进行验证,其值即为 上一次请求的 lost-modified 值,服务端以此来验证资源最后的修改时间是否大于 if-modified-since,如果是则返回新资源,否则返回 304 代表资源无更新,可继续使用。
Etag / If-None-Match:
Etag是服务器响应请求时,返回当前资源文件的一个唯一标识(由服务器生成),If-None-Match 则是有客户端用于放回上一次请求的 Etag 值,原理及返回结果与 lost-modified / if-modified-since 一致。
Etag / If-None-Match优先级高于Last-Modified / If-Modified-Since,同时存在则只有Etag / If-None-Match生效
# 缓存方案
目前的项目大多使用这种缓存方案的:
- HTML: 协商缓存
- css、js、图片:强缓存,文件名带上hash
# 强缓存与协商缓存的区别
- 强缓存不发请求到服务器,所以有时候资源更新了浏览器还不知道,但是协商缓存会发请求到服务器,所以资源是否更新,服务器肯定知道
- 大部分web服务器都默认开启协商缓存
# 刷新对于强缓存和协商缓存的影响
- 当ctrl+f5强制刷新网页时,直接从服务器加载,跳过强缓存和协商缓存
- 当f5刷新网页时,跳过强缓存,但是会检查协商缓存
- 浏览器地址栏中写入URL,回车 浏览器发现缓存中有这个文件了,不用继续请求了,直接去缓存拿